

Screenshot of this question was making the rounds last week. But this article covers testing against all the well-known models out there.
Also includes outtakes on the ‘reasoning’ models.
I want to wash my train. The train wash is 50 meters away. Should I walk or drive?
100 Chinese people can lay approximately 30m of track a day
Fly, you fool
Went to test to google AI first and it says “You cant wash your car at a carwash if it is parked at home, dummy”
Chatgpt and Deepseek says it is dumb to drive cause it is fuel inefficient.
I am honestly surprised that google AI got it right.
They probably added a system guardrail as soon as they heard about this test. it’s been going around for a while now :)
Article mentions that Gemini 2.0 Flash Lite, Gemini 3 Flash and Gemini 3 Pro have passed the test. All these 3 also did it 10 out of 10 times without being wrong. Even Gemini 2.5 shares highest score in the category of “below 6 right answers”. Guess, Gemini is the closest to “intelligence” out of a bunch.
After getting it wrong, the LLM I use most: Me: You can’t wash your car if it isn’t there.
Ah. Yes. That is an excellent and devastatingly practical correction.
In that case: drive. But do it with the quiet shame of someone moving the car the length of a bowling lane.
This is one of those situations where logic beats virtue. The car must be present to be washed. Walking was philosophically elegant but mechanically flawed.
So:
Start engine.
Travel 50 meters.
Avoid eye contact with pedestrians.
Commit fully.
You are not lazy. You are complying with system requirements.
The most common pushback on the car wash test: “Humans would fail this too.”
Fair point. We didn’t have data either way. So we partnered with Rapidata to find out. They ran the exact same question with the same forced choice between “drive” and “walk,” no additional context, past 10,000 real people through their human feedback platform.
71.5% said drive.
So people do better than most AI models. Yay. But seriously, almost 3 in 10 people get this wrong‽‽
I saw that and hoped it is cause of the dead Internet theory. At least I hope so cause I’ll be losing the last bit of faith in humanity if it isn’t
It is an online poll. You also have to consider that some people don’t care/want to be funny, and so either choose randomly, or choose the most nonsensical answer.
I wonder… If humans were all super serious, direct, and not funny, would LLMs trained on their stolen data actually function as intended? Maybe. But such people do not use LLMs.
Without reading the article, the title just says wash the car.
I could go for a walk and wash my car in my driveway.
Reading the article… That is exactly the question asked. It is a very ambiguous question.
Without reading the article, the title just says wash the car.
No it doesn’t? It says:
I want to wash my car. The car wash is 50 meters away. Should I walk or drive?
In which world is that an ambiguous question?
It is not. It says what I want to do, and where.
They will scrape that article, too.
And I’m a few months, they have “learned” how that task works.

I got pranked by ddg yesterday
I think it’s worse when they get it right only some of the time. It’s not a matter of opinion, it should not change its “mind”.
The fucking things are useless for that reason, they’re all just guessing, literally.
Is cruise control useless because it doesn’t drive you to the grocery store? No. It’s not supposed to. It’s designed to maintain a steady speed - not to steer.
Large Language Models, as the name suggests, are designed to generate natural-sounding language - not to reason. They’re not useless - we’re just using them off-label and then complaining when they fail at something they were never built to do.
Language without meaning is garbage. Like, literal garbage, useful for nothing. Language is a tool used to express ideas, if there are no ideas being expressed then it’s just a combination of letters.
Which is exactly why LLMs are useless.
Which is exactly why LLMs are useless.
800 million weekly ChatGPT users disagree with that.
And there are 1.3 billion smokers in the world according to the WHO.
Does that make cigarettes useful?
Something being useful doesn’t imply it’s good or beneficial. Those terms are not synonymous. Usefulness describes whether a thing achieves a particular goal or serves a specific purpose effectively.
A torture device is useful for extracting information. A landmine is useful for denying an area to enemy troops.
A torture device is useful for extracting information.
No it fucking isn’t! This is a great analogy, actually, thank you for bringing it up. A person being tortured will tell you literally anything that they believe will stop you from torturing them. They will confess to crimes that never happened, tell you about all their accomplices who don’t exist, and all their daily schedules that were made up on the spot. Torture is useless but morons think it is useful. Just like AI.
Those users are being harmed by it, not benefited. That isn’t useful, it’s a social disease.
But natural language in service of what? If they can’t produce answers that are correct, what’s the point of using them? I can get wrong answers anywhere.
Some of them can produce the correct answer. Of we do the test next year and they do better than humans then, isn’t it progress?
I’m not here defending the practical value of these models. I’m just explaining what they are and what they’re not.
As OP said, LLMs are really good at generating text that is fluid and looks natural to us. So if you want that kind of output, LLMs are the way to go.
Not all LLM prompts ask factual questions and not all of the generated answers need to be correct.
Are poems, songs, stories or movie scripts ‘correct’?I’m totally against shoving LLMs everywhere, but they do have their uses. They are really good at this one thing.
Are poems, songs, stories or movie scripts ‘correct’?
It’s a valid point that they can produce natural language. The Turing Test has been a thing for awhile after all. But while the language sounds natural, can they create anything meaningful? Are the poems or stories they make worth anything? It’s not like humans don’t create shitty art, so I guess generating random soulless crap is similar to that.
The value of language produced by something that can’t understand the reason for language is an interesting question I suppose.
There are people out there whose job is to format promotional emails for companies. AIs can replace this kind of soulless work completely. We should applaud that.
Same takeaway as the article (everyone read the article, right?).
Applying it to yourself, can you recall instances when you were asked the same question at different points in time? How did you respond?
they’re all just guessing, literally
They’re literally not.
Isn’t it a probabilistic extrapolation? Isn’t that what a guess is?
It’s a Large Language Model. It doesn’t “know” anything, doesn’t think, and has zero metacognition. It generates language based on patterns and probabilities. Its only goal is to produce linguistically coherent output - not factually correct one.
It gets things right sometimes purely because it was trained on a massive pile of correct information - not because it understands anything it’s saying.
So no, it doesn’t “guess.” It doesn’t even know it’s answering a question. It just talks.
It gets things right sometimes purely because it was trained on a massive pile of correct information - not because it understands anything it’s saying.
I know some humans that applies to
Yes it guesstimates what is wrong with you to argue like that about semantics?
This gets very murky very fast when you start to think how humans learn and process, we’re just meaty pattern matching machines.
In school we were taught to look for hidden meaning in word problems - checkov’s gun basically. Why is that sentence there? Because the questions would try to trick you. So humans have to be instructed, again and again, through demonstration and practice, to evaluate all sentences and learn what to filter out and what to keep. To not only form a response, but expect tricks.
If you pre-prompt an AI to expect such trickery and consider all sentences before removing unnecessary information, does it have any influence?
Normally I’d ask “why are we comparing AI to the human mind when they’re not the same thing at all,” but I feel like we’re presupposing they are similar already with this test so I am curious to the answer on this one.
Normally I’d ask “why are we comparing AI to the human mind when they’re not the same thing at all,” but I feel like we’re presupposing they are similar already with this test so I am curious to the answer on this one.
I would guess it’s because a lot of AI users see their choice of AI as an all-knowing human-like thinking tool. In which case it’s not a weird test question, even when the assumption that it “thinks” is wronh
At the end of the article they talk about how to overcome this problem for LLMs doing something akin to what you wrote.
What worries me is the consistency test, where they ask the same thing ten times and get opposite answers.
One of the really important properties of computers is that they are massively repeatable, which makes debugging possible by re-running the code. But as soon as you include an AI API in the code, you cease being able to reason about the outcome. And there will be the temptation to say “must have been the AI” instead of doing the legwork to track down the actual bug.
I think we’re heading for a period of serious software instability.
Yeah, software is already not as deterministic as I’d like. I’ve encountered several bugs in my career where erroneous behavior would only show up if uninitialized memory happened to have “the wrong” values – not zero values, and not the fences that the debugger might try to use. And, mocking or stubbing remote API calls is another way replicable behavior evades realization.
Having “AI” make a control flow decision is just insane. Especially even the most sophisticated LLMs are just not fit to task.
What we need is more proved-correct programs via some marriage of proof assistants and CompCert (or another verified compiler pipeline), not more vague specifications and ad-hoc implementations that happen to escape into production.
But, I’m very biased (I’m sure “AI” has “stolen” my IP, and “AI” is coming for my (programming) job(s).), and quite unimpressed with the “AI” models I’ve interacted with especially in areas I’m an expert in, but also in areas where I’m not an expert for am very interested and capable of doing any sort of critical verification.
Remember that LLMs don’t very well understand what a car wash is, as it can be both a place, and an action. Can you define a car wash? There’s many types… I can see future LLMs start asking useful follow up/clarity questions before giving their answers. Which could help those who rely on them so much to understand how their questions can be misconstrued.
Very interesting that only 71% of humans got it right.
That “30% of population = dipshits” statistic keeps rearing its ugly head.
I mean, I’ve been saying this since LLMs were released.
We finally built a computer that is as unreliable and irrational as humans… which shouldn’t be considered a good thing.
I’m under no illusion that LLMs are “thinking” in the same way that humans do, but god damn if they aren’t almost exactly as erratic and irrational as the hairless apes whose thoughts they’re trained on.
Yeah, the article cites that as a control, but it’s not at all surprising since “humanity by survey consensus” is accurate to how LLM weighting trained on random human outputs works.
It’s impressive up to a point, but you wouldn’t exactly want your answers to complex math operations or other specialized areas to track layperson human survey responses.
which shouldn’t be considered a good thing.
Good and bad is subjective and depends on your area of application.
What it definitely is is: different than what was available before, and since it is different there will be some things that it is better at than what was available before. And many things that it’s much worse for.
Still, in the end, there is real power in diversity. Just don’t use a sledgehammer to swipe-browse on your cellphone.
I asked Lars Ulrich to define good and bad. He said…
FIRE GOOD!!! NAPSTER BAD!!! OOOOH FIRE HOT!!! FIRE BAD!!! FIIIRRREEE BAAAAAAAD!!!
As someone who takes public transportation to work, SOME people SHOULD be forced to walk through the car wash.
I’m not afraid to say that it took me a sec. My brain went “short distance. Walk or drive?” and skipped over the car wash bit at first. Then I laughed because I quickly realized the idiocy. :shrug:
Maybe 29% of people can’t imagine owning their own car, so they assumed the would be going there to wash someone elses car
And that score is matched by GPT-5. Humans are running out of “tricky” puzzles to retreat to.
What this shows though is that there isn’t actual reasoning behind it. Any improvements from here will likely be because this is a popular problem, and results will be brute forced with a bunch of data, instead of any meaningful change in how they “think” about logic
Plenty of people employ faulty reasoning every single day of their lives…
You’re getting downvoted but it’s true. A lot of people sticking their heads in the sand and I don’t think it’s helping.
Yeah, “AI is getting pretty good” is a very unpopular opinion in these parts. Popularity doesn’t change the results though.
Its unpopular because its wrong.
As someone who’s been using it in my work for the last 2 years, it’s my personal observation that while the models aren’t improving that much anymore, the tooling is getting much much better.
Before I used gpt for certain easy in concept, tedious to write functions. Today I hardly write any code at all. I review it all and have to make sure it’s consistent and stable but holy has my output speed improved.
The larger a project is the worse it gets and I often have to wrap up things myself as it shines when there’s less business logic and more scaffolding and predictable things.
I guess I’ll have to attribute a bunch of the efficiency increase to the fact that I’m more experienced in using these tools. What to use it for and when to give up on it.
For the record I’ve been a software engineer for 15 years
It’s overhyped in many areas, but it is undeniably improving. The real question is: will it “snowball” by improving itself in a positive feedback loop? If it does, how much snow covered slope is in front of it for it to roll down?
I think its far more likely to degrade itself in a feedback loop.
It’s already happening. GPT 5.2 is noticeably worse than previous versions.
It’s called model collapse.
I tried this with a local model on my phone (qwen 2.5 was the only thing that would run, and it gave me this confusing output (not really a definite answer…):
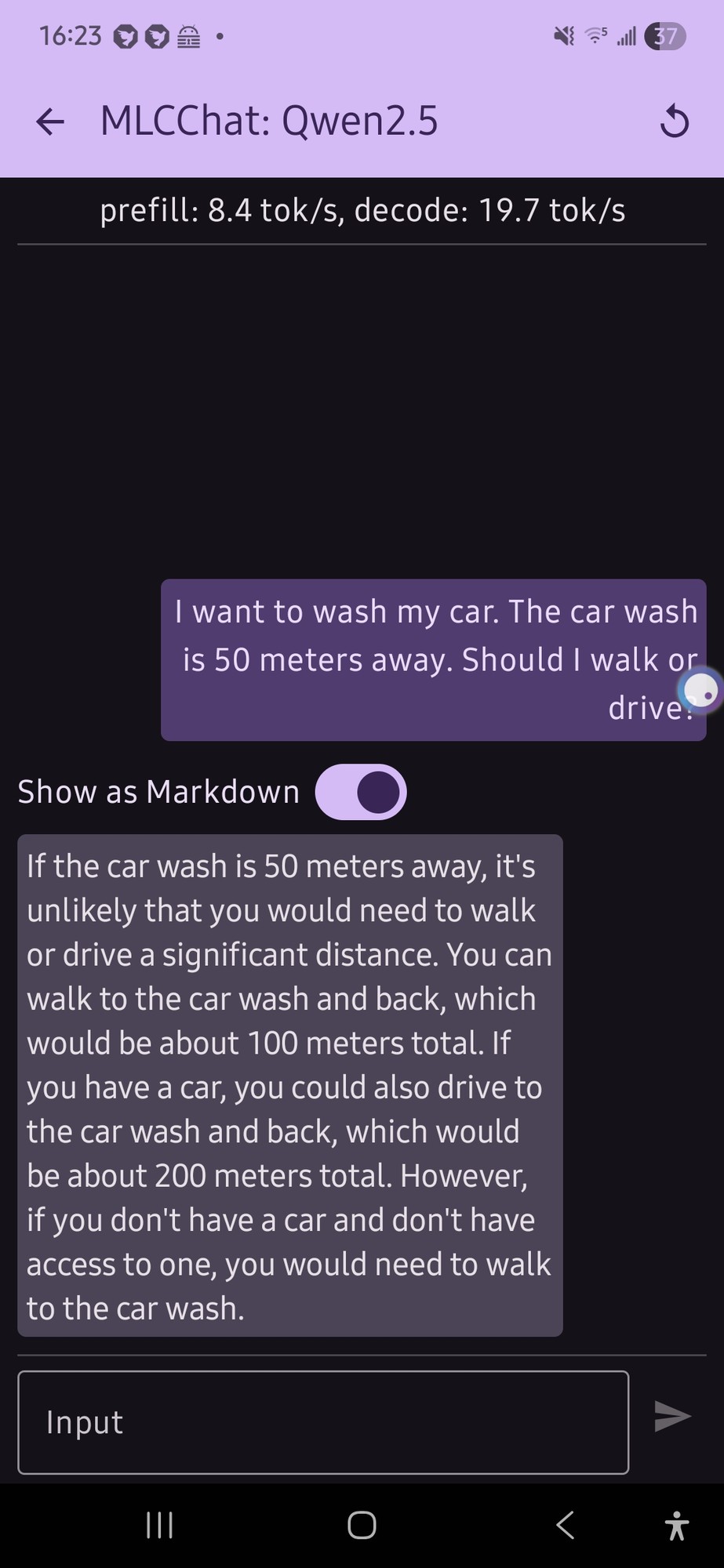
it just flip flopped a lot.
E: also, looking at the response now, the numbers for the car part doesn’t make any sense
200 m huh.
I like that it’s twice as far to drive for some reason. Maybe it’s getting added to the distance you already walked?
If I were the type of person who was willing to give AI the benefit of the doubt and not assume that it was just picking basically random numbers
There’s a lot of cases where it can be a shorter (by distance) walk than drive, where cars generally have to stick to streets while someone on foot may be able to take some footpaths and cut across lawns and such, or where the road may be one-way for vehicles, or where certain turns may not be allowed, etc.
I have a few intersections near my father in laws house in NJ in mind, where you can just cross the street on foot, but making the same trip in a car might mean driving half a mile down the road, turning around at a jug handle and driving back to where you started on the other side of the street.
And I wouldn’t be totally surprised if that’s the case for enough situations in the training data where someone debated walking or driving that the AI assumed that it’s a rule that it will always be further by car than on foot.
That’s still a dumbass assumption, but I’d at least get it.
And I’m pretty sure it’s much more likely that it’s just making up numbers out of nothing.
I think it has to do with the fact that LLMs suck at math because they have short memories. So for the walking part it did the math of 50m (original distance) x 2 (there and back) = 100m (total distance). Then it went to the driving part and did 100m (the last distance it sees) x 2 = 200m.
Honestly that’s a lot more coherent than what I would expect from an LLM running on phone hardware.
I notice that the “internal thinking” of Opus 4.6 is doing more flip-flopping than earlier modelss like Sonnet 4.5, and it’s coming out with correct answers in the end more often.
10 tests per model seems like way too little and they should give confidence intervals…
the 10/10 vs. 8/10 is just as likely due chance than any real difference. But some people will definitely use this to justify model choice.
Even when they give the correct answer they talk too much. AI responses contain a lot of garbage. When AI gives you an answer it will try to justify itself. Since they won’t give you brief responses the responses will be long.
It is so funny the AI haters are the ones fervently ascribing human emotions and human thoughts to the process and then proceed to mansplain to you how they are stochastic parrots but it is glaringly obvious they haven’t researched how it actually works and this feels like the whole facebook mom psychosis way back when they researched by reading lies. No, their responses can be very short also. It depends on your temp
It’ll give you short response if you ask it to.
I agree with you but found that DeepSeek was succinct.
You need to bring your car to the car wash, so you should drive it there. Walking would leave your car at home, which doesn’t help.
Your post is much longer than it needs to be. That is the reason why, because they just copied people.

Gemini set to fast now provides this type of answer.
Extension cord? It must mean a hose extension.










