
cross-posted from: https://discuss.tchncs.de/post/13814482
I just noticed that
ezacan now display total disk space used by directories!I think this is pretty cool. I wanted it for a long time.
There are other ways to get the information of course. But having it integrated with all the other options for listing directories is fab.
ezahas features like--git-awareness,--treedisplay, clickable--hyperlink, filetype--iconsand other display, permissions, dates, ownerships, and other stuff. being able to mash everything together in any arbitrary way which is useful is handy. And of course you can--sort=sizedocs:
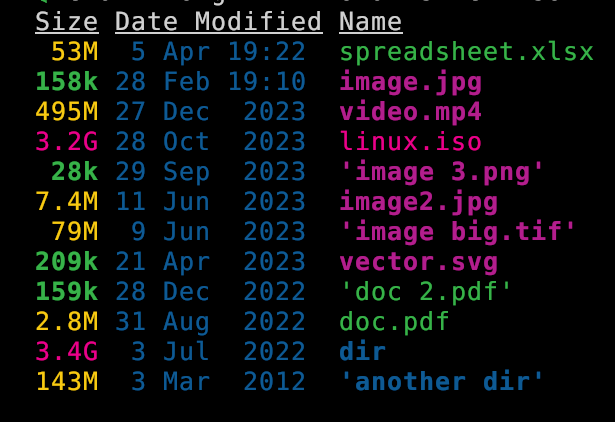
--total-size show the size of a directory as the size of all files and directories inside (unix only)It also (optionally) color codes the information. Values measures in kb, mb, and gb are clear. Here is a screenshot to show that:
eza --long -h --total-size --sort=oldest --no-permissions --no-user
Of course it take a little while to load large directories so you will not want to use by default.
Looks like it was first implemented Oct 2023 with some fixes since then. (Changelog). PR #533 - feat: added recursive directory parser with `–total-size` flag by Xemptuous
Off topic, but maybe someone will appreciate this. I wrote a function to get the size of contents of a dir a while back. It has a couple of dependencies (
gc,gwcat a glance), but should be fairly portable. The results are sorted from greatest to least as shown in the screenshot.Is this effectively the same as:
du -hs * | sort -h?Hahaha. I may have spent a lot of time creating a script to implement functionality that was already there.
du -hs * | sort -h -r, I guess.Thanks! I always appreciate another tool for this. I tried to run it but have dep issues.
What is
gwc? I can’t find a package by that name nor is it included that I can see.Websearch finds GeoWebCache, Gnome Wave Cleaner, GtkWaveCleaner, several IT companies… nothing that looks relevant.
edit: also stumped looking for
gsort. it seems to be associated with something called STATA which is statistical analysis software. Is that something you are involved with maybe running some special stuff on your system?PS you missed a newline at the end before closing the code block which is why the image was showing up as markdown instead of displaying properly.
Change:
}```to:
} ```Aha with the new line! Thank you!
I believe
gwcandgsortare part ofcoreutilsbased on this:$ gwc --help Usage: gwc [OPTION]... [FILE]... or: gwc [OPTION]... --files0-from=F Print newline, word, and byte counts for each FILE, and a total line if more than one FILE is specified. A word is a nonempty sequence of non white space delimited by white space characters or by start or end of input. With no FILE, or when FILE is -, read standard input. The options below may be used to select which counts are printed, always in the following order: newline, word, character, byte, maximum line length. -c, --bytes print the byte counts -m, --chars print the character counts -l, --lines print the newline counts --files0-from=F read input from the files specified by NUL-terminated names in file F; If F is - then read names from standard input -L, --max-line-length print the maximum display width -w, --words print the word counts --total=WHEN when to print a line with total counts; WHEN can be: auto, always, only, never --help display this help and exit --version output version information and exit GNU coreutils online help: <https://www.gnu.org/software/coreutils/> Full documentation <https://www.gnu.org/software/coreutils/wc> or available locally via: info '(coreutils) wc invocation'